視野検査AIによる検査時間の短縮と高精度化
【研究のポイント】
・視野検査を制御するエージェントの学習フレームワークを確立した
・人の光への反応の不確かさを考慮した視野検査シミュレータを用いることによって、多様な人への検査がロバストに学習できる
・デファクトスタンダードで用いられている従来の検査アルゴリズムと比較して、半分以下の検査時間で同等以上の検査精度を達成した
【研究の概要】
視野検査は視野欠損を伴う疾患に対して実施される検査である。視野検査は被検者の負担が大きく、より短い時間で正確に検査することが求められている。本研究では、この視野検査を制御する視野検査AIのViFT(Visual Field Transformer)を深層強化学習するフレームワークの構築を行なった。このフレームワークでは、ViFTを学習するために、検査中の人の反応の不確かさをモデル化した視野検査シミュレーションを用いて深層強化学習を行なった。今まで人手で設計していた視野の空間的な関係を、ViFTは深層強化学習の過程でデータから学習する。その結果、ViFTは従来の手法と比較して半分以下の時間で同等以上の精度で検査が実施可能であることを示した。
視野は人のQoL(Quality of Life)と密接に関係しており、視野欠損は人のQoLを低下させる要因となる。特に、視野欠損が生じる緑内障は、全世界で約7600万人が患っていると予想されており、日本においては40歳以上での有病率は5%と言われている。視野欠損などが生じる疾患において診断や視野欠損の進行度を評価するために視野検査は用いられ、視野欠損の進行度を適切に評価するために、視野検査は定期的な検査が推奨されている。視野検査とは、人の網膜に光の刺激を与えて、主に視野の中心30度の網膜感度を計測する検査である。しかし、視野検査は顔と視線を固定した状態で、10分から30分程度、光が見えたらボタンを押すという自覚的な作業に基づいた検査である。そのため、被験者の負担が大きく、長時間の検査は検査の信頼性の低下につながる。
本研究では、視野検査で光によって刺激する網膜の位置と明るさを決定する視野検査エージェントを深層強化学習するフレームワークを確立した。このフレームワークは、ニューラルネットワークの検査エージェントのViFT(Visual Field Transformer)と視野検査シミュレータで構成される。ViFTでは、Transformerと呼ばれるニューラルネットワークの構造を用いて、今まで人手で設計していた視野の空間的な関係をViFTがデータから学習する。視野検査シミュレータでは、人が光を知覚できるかどうか確率的にシミュレーションする。このシミュレータでは、シミュレーションしている視野に対して、誤回答率の異なる被検者をランダムに割り当て、よりリアルなシミュレーションを行った。このようなフレームワークで学習したViFTは従来の視野検査アルゴリズムと比較して、半分以下の光の呈示回数で検査が実施できた。さらに、精度についても誤回答率の異なる幅広い被検者に対して、従来アルゴリズムと同等以上の精度であった。特に、誤回答率の高い被験者においても、ViFTは安定した精度での検査が可能であった。したがって、ViFTは従来の視野検査アルゴリズムと比較して、半分以下の検査時間で高い精度で安定した検査を実現できる。これらの成果は、視野検査の信頼性と精度を高め、被検者の負担を大幅に低減することに寄与する。
論文情報
ViFT: Visual field transformer for visual field testing via deep reinforcement learning,
Shozo Saeki, Minoru Kawahara, Hirohisa Aman,
Medical Image Analysis, Vol. 105, pp. 103721,
doi:10.1016/j.media.2025.103721, 2025.
助成金等
- JSPS 科研費 JP23K11322
図表等
-
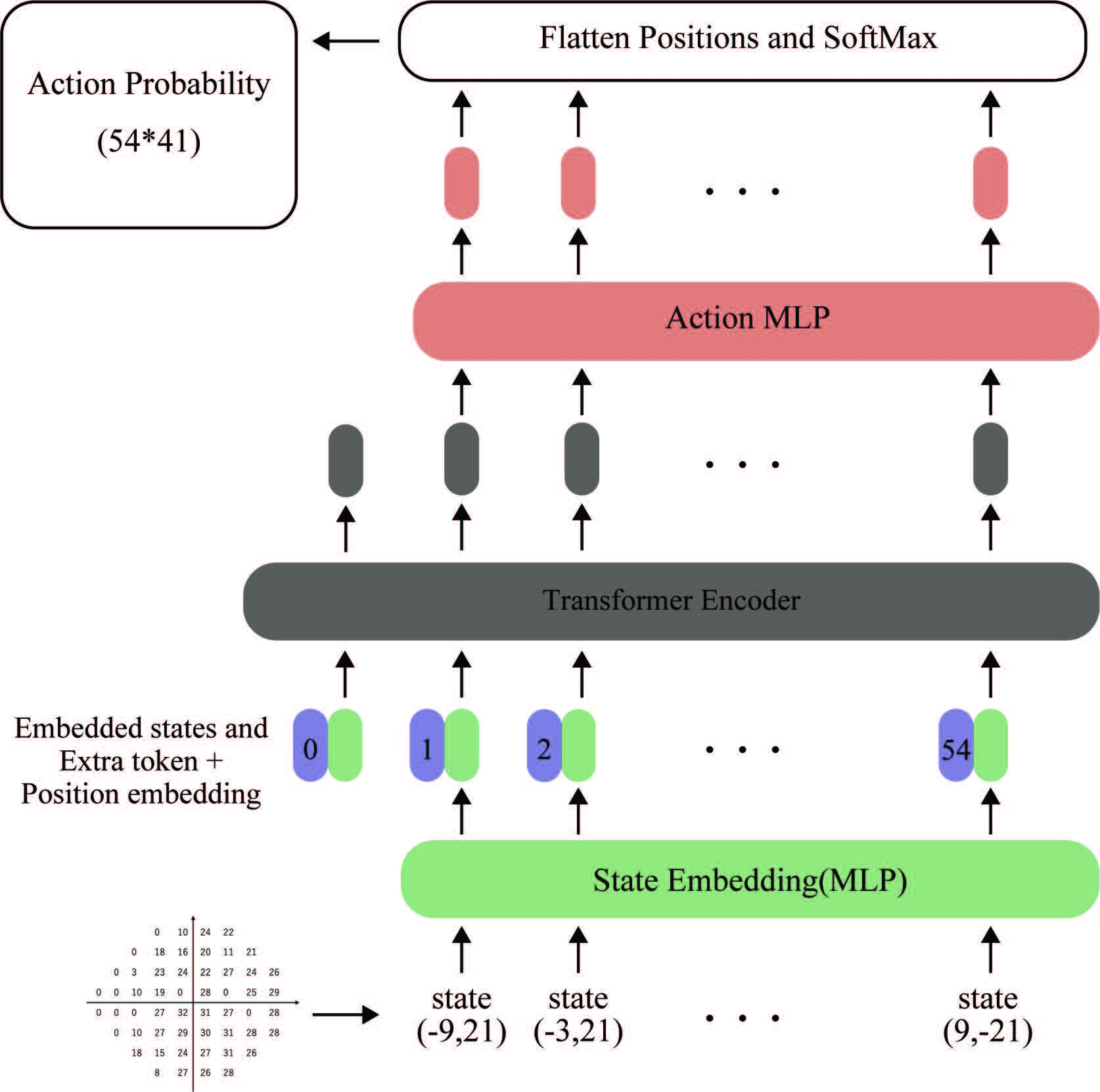
ViFTのモデル構造
入力として視野検査の検査座標ごとの計測履歴を受け取り、次の検査光の座標と刺激強度の確率を出力を行う。Transformerの構造により、視野の空間的な関係性を学習する。
credit : 佐伯 昌造(愛媛大学)
Usage Restriction : 使用許可を得てください
問い合わせ先
氏名 : 佐伯 昌造
電話 : 089-927-8353
E-mail : saeki.shozo.cg@ehime-u.ac.jp
所属 : 愛媛大学総合情報メディアセンター