ViFT: Perimetry AI for Reducing Test Time and High Accuracy
Perimetry (visual field testing) quantifies a patient’s retinal sensitivity to light and clarifies a deviation from normal retinal sensitivity. Visual field tests generally require high patient concentration, which can be exhausted. We constructed a framework for deep reinforcement learning to train ViFT (Visual Field Transformer), which controls all processes of visual field testing. ViFT achieves the same or higher accuracy than the state-of-the-art strategies, with less than half the test time of the state-of-the-art strategies.
Visual field is deeply related to QoL (Quality of Life), and visual field defects are a factor that lowers quality of life. Especially, it is estimated that 76 million people worldwide suffer from glaucoma, which causes visual field defects, as reported in 2020. Visual field testing is one of the most common tests in clinical practice and the standard for diagnosis and follow-up for eye diseases with visual field defects. Visual field testing stimulates a patient’s retina with light and quantifies the patient’s retinal sensitivity. This test generally takes a long time, between 10 and 30 minutes per eye. Additionally, this test also requires patients to concentrate and fix their posture while undergoing testing. Thus, visual field testing makes a patient exhausted. This fatigue reduces the reliability of the visual field test results because the test relies on patient responses.
This study establishes the framework for learning agents in visual field testing to make the test faster and more reliable. This framework has two components: ViFT (Visual Field Transformer) and a visual field testing simulator. ViFT receives test histories and determines the next test location and intensity of stimulus. ViFT can learn the relationships of visual field locations without any pre-defined information because ViFT has transformer structures. This feature contributes to the efficient test. The visual field testing simulator simulates human responses to stimuli determined by ViFT. These responses are determined based on two factors: the retinal sensitivities of real patients and patient perceptual uncertainty, such as false-positive or false-negative responses. In the learning process, simulated patients are assigned patient perceptual uncertainty randomly. As a result of learning in this framework, ViFT achieves the same or higher accuracy than the state-of-the-art strategies, with half the number of stimulus presentations as the state-of-the-art strategies. Therefore, ViFT can reduce the test time by half. Additionally, ViFT can facilitate stable visual field testing for patients who provide many incorrect answers, as ViFT is trained on simulated patients with various perceptual uncertainties. This study contributes to highly reliable and accurate visual field testing, and ViFT can reduce the burden on patients.
Bibliographic Information
ViFT: Visual field transformer for visual field testing via deep reinforcement learning,
Shozo Saeki, Minoru Kawahara, Hirohisa Aman,
Medical Image Analysis, Vol. 105, pp. 103721,
doi:10.1016/j.media.2025.103721, 2025.
Fundings
- JSPS KAKENHI Grant Number JP23K11322
Media
-
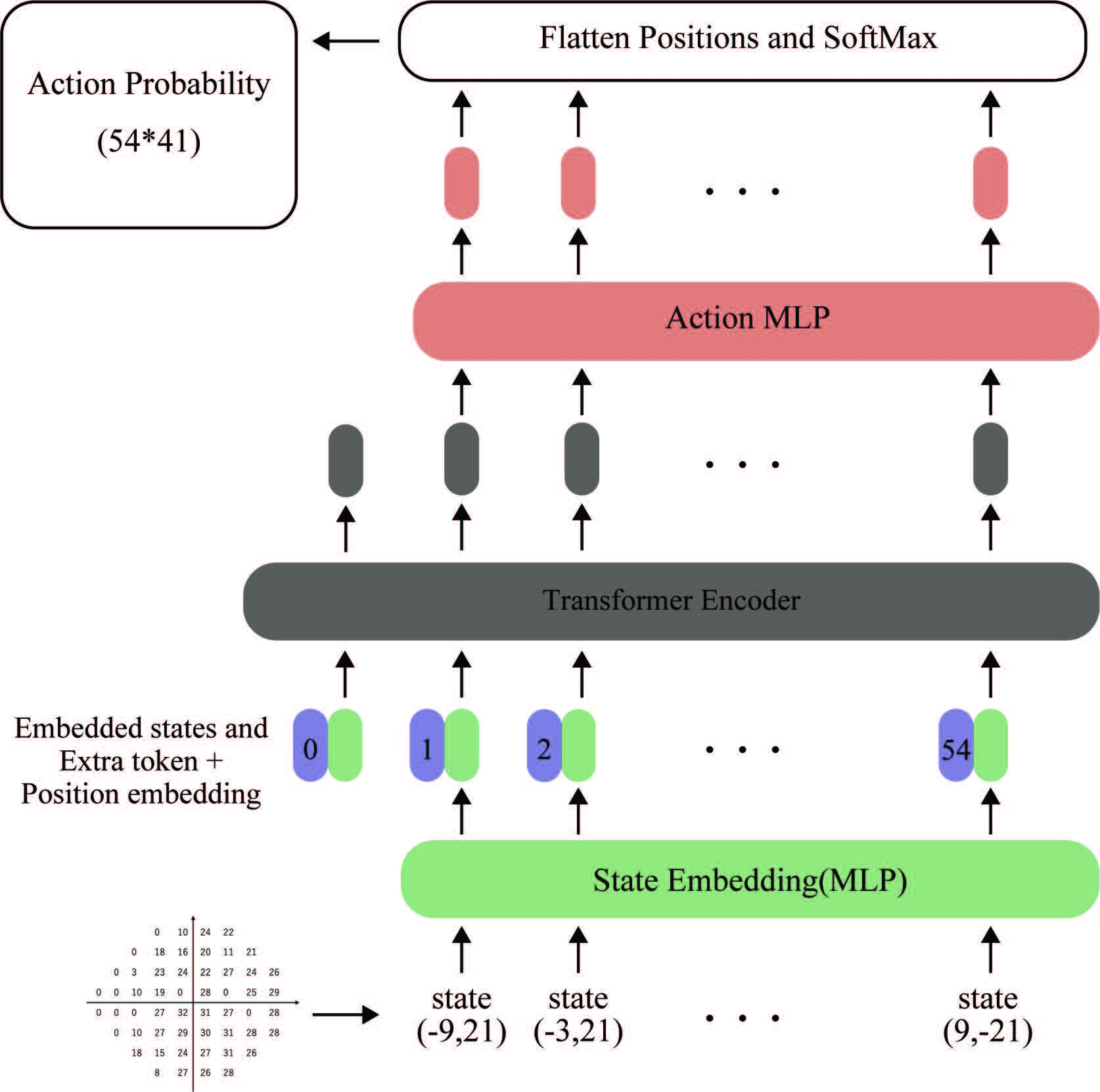
ViFT structure
ViFT receives test histories for each test location and determines the next test location and intensity of stimulus. ViFT can learn the spatial relationships because ViFT has transformer structures.
credit : Shozo Saeki
Usage Restriction : Please get copyright permission
Contact Person
Name : Shozo Saeki
Phone : +81 89-927-8353
E-mail : saeki.shozo.cg@ehime-u.ac.jp
Affiliation : Center for Information Technology, Ehime University